Il software è entropia
Tutti oggi possono scrivere software. Ma scrivere non è mantenere, e l'entropia non si delega. Una riflessione sull'illusione del vibe coding, sul costo vero dei bug, e sul perché l'ingegneria del software, lungi dallo sparire, oggi conta più di prima.

Tutti oggi possono scrivere software. Ma scrivere non è mantenere, e l'entropia non si delega. Una riflessione sull'illusione del vibe coding, sul costo vero dei bug, e sul perché l'ingegneria del software, lungi dallo sparire, oggi conta più di prima.
Scrivere codice non è mai stato così facile. Manutenerlo non è mai stato così difficile.
Una sera davanti al monitor
È una sera qualunque. La tazza dell’orzo è fredda da un’ora, ma me ne accorgo solo ora che sto guardando lo schermo da troppo tempo. Da qualche tempo ho deciso di bere un solo caffè al giorno, e questo l’ho già speso stamattina. Quindi orzo, e tra poco probabilmente un infuso. Sto facendo la review di un progetto. Non è un progetto mio: è uno di quei progetti che oggi si chiamano vibe-codati, scritti quasi interamente lasciandosi guidare dall’AI, da una serie di prompt e accettazioni a catena.
Sul monitor, due finestre affiancate. A sinistra il terminale, con Claude Code in attesa, pronto a rispondere al prossimo input. A destra Neovim, con cui sto sfogliando il codice riga per riga. Apro un file, poi un altro, poi un altro ancora. Ogni file, da solo, sembra ragionevole. Funzioni con nomi sensati, qualche commento, persino qualche test che gira verde.
Eppure, mentre scorro, sento quella cosa che chi programma da anni conosce bene: un fastidio sordo. Non un errore di sintassi, non un bug puntuale. Un fastidio strutturale. Decido di smettere di andare a naso e di chiamare in causa uno strumento. Imposto PHPStan a livello 7, lancio l’analisi, e mentre scorre l’output capisco che la sensazione era ben fondata: 495 errori. Quattrocentonovantacinque. Ok. C’è decisamente del lavoro da fare.
Continuo a scorrere. Trovo funzioni che assumono cose che da nessun’altra parte sono garantite. Lo stesso pezzo di logica replicato in tre punti, ogni volta con una piccola variante. Chiamate a tre librerie diverse che fanno la stessa cosa, perché in tre prompt diversi l’AI ha proposto tre soluzioni diverse e nessuno si è preoccupato di unificarle. Modelli di dati che si contraddicono tra un modulo e l’altro. Type hint mancanti, valori di ritorno ambigui, nullable trattati come se fossero garantiti.
Funziona. Tutto funziona. Le funzionalità ci sono, l’utente medio non si accorgerebbe di nulla. Ma io so, perché ne ho viste tante, che quel codice è una bomba a orologeria. Fra sei mesi, quando qualcuno chiederà di aggiungere una feature che attraversa tutti quei moduli, salterà tutto in aria.
Chiudo Neovim. Chiudo il terminale. Mi alzo per prendere un altro orzo, o forse mi faccio direttamente un infuso di cicoria. Devo pensare. So già che la decisione, alla fine, sarà di rifarlo da capo.
E mi viene in mente una slide.
Il talk del 2024
Nel 2024 ho tenuto un talk al MOCA, il Metro Olografix Camp, sullo sviluppo rapido di applicazioni web. Era un talk molto pratico, su Laravel e Filament, due strumenti che mi permettono di tirare su un’applicazione completa, autenticata, con interfaccia amministrativa decente, in poche ore. Le slide le avevo finite la mattina stessa, in puro stile test in produzione. Una di quelle slide era nera, scritte bianche, e diceva una sola cosa.
“Il software è come l’entropia. È difficile da afferrare, non pesa nulla e obbedisce alla seconda legge della termodinamica: aumenta sempre.”
Norman R. Augustine, 17ª legge di Augustine.
Augustine era un ex pilota dell’aeronautica americana, poi a lungo dirigente nell’industria aerospaziale. Ha messo per iscritto una serie di leggi mezze ironiche e mezze tragiche su come funziona davvero la complessità nei progetti grandi. La diciassettesima è la mia preferita, perché è la più onesta.
L’entropia, nel senso termodinamico, è la misura del disordine. Il secondo principio della termodinamica dice che, in un sistema isolato, l’entropia non può che aumentare. Le cose tendono a sfasciarsi, a disorganizzarsi, a perdere struttura. Per riportare ordine bisogna fare lavoro: spendere energia, dall’esterno, per ricomporre il sistema. Il software, dice Augustine, si comporta esattamente così. Tende al disordine. Ogni nuova feature aggiunta in fretta, ogni dipendenza aggiornata senza guardare bene, ogni quick fix lasciato in produzione “per ora”, aumenta il disordine. Se nessuno spende lavoro per ridurlo, il disordine vince. Sempre.
Ecco: questa cosa, in oltre vent’anni di mestiere, l’ho vista succedere ovunque. E non è un problema dell’AI. È un problema strutturale del software.
Il software è un sistema complesso
Pensateci. Un’applicazione web qualsiasi non è un blocco di codice. È un ecosistema. C’è il codice che noi scriviamo, sì, ma sotto ci sono decine di librerie di terze parti, ognuna con la sua logica, le sue versioni, i suoi bug. C’è un database, che ha le sue regole su cosa può e non può accadere ai dati. C’è un sistema operativo, ci sono container, c’è una rete con le sue latenze imprevedibili. C’è un browser dall’altra parte, anzi, ci sono mille browser diversi su mille dispositivi diversi. Ci sono utenti che fanno cose che il progettista non aveva immaginato. Ci sono integrazioni con sistemi esterni che possono cambiare API senza preavviso. Ci sono requisiti di business che cambiano ogni trimestre.
Ogni componente, da solo, è gestibile. È nelle interazioni che nasce la complessità vera. E le interazioni crescono, in modo combinatorio, molto più velocemente del numero di componenti.
A questo si aggiunge la legge di Brooks, vecchia di cinquant’anni e ancora valida: aggiungere persone a un progetto in ritardo lo farà ritardare ancora di più. Perché un team più grande significa più canali di comunicazione, più decisioni da allineare, più contesto da mantenere coerente. La complessità non è solo nel codice: è nel team che lo scrive.
Quando si parla di “produrre software”, la maggior parte delle persone pensa alla scrittura del codice. Ma la verità, e qui c’è uno dei dati più sottovalutati di tutta l’industria, è che la scrittura iniziale è la fetta più piccola del costo totale.
Il costo vero è il mantenimento
Esiste un grafico che ho usato in quel talk, ripreso a sua volta da Enrico Zimuel, che mostra il costo relativo per correggere un bug a seconda della fase in cui viene scoperto. Il modello è semplice. Mettiamo come unità di misura il costo di correggere un bug in fase di analisi dei requisiti: 1. Lo stesso bug scoperto in fase di sviluppo costa circa 5 volte tanto. In fase di integration testing, una decina. In fase di accettazione, una quindicina. In produzione, dopo il rilascio, fino a 30 volte tanto.
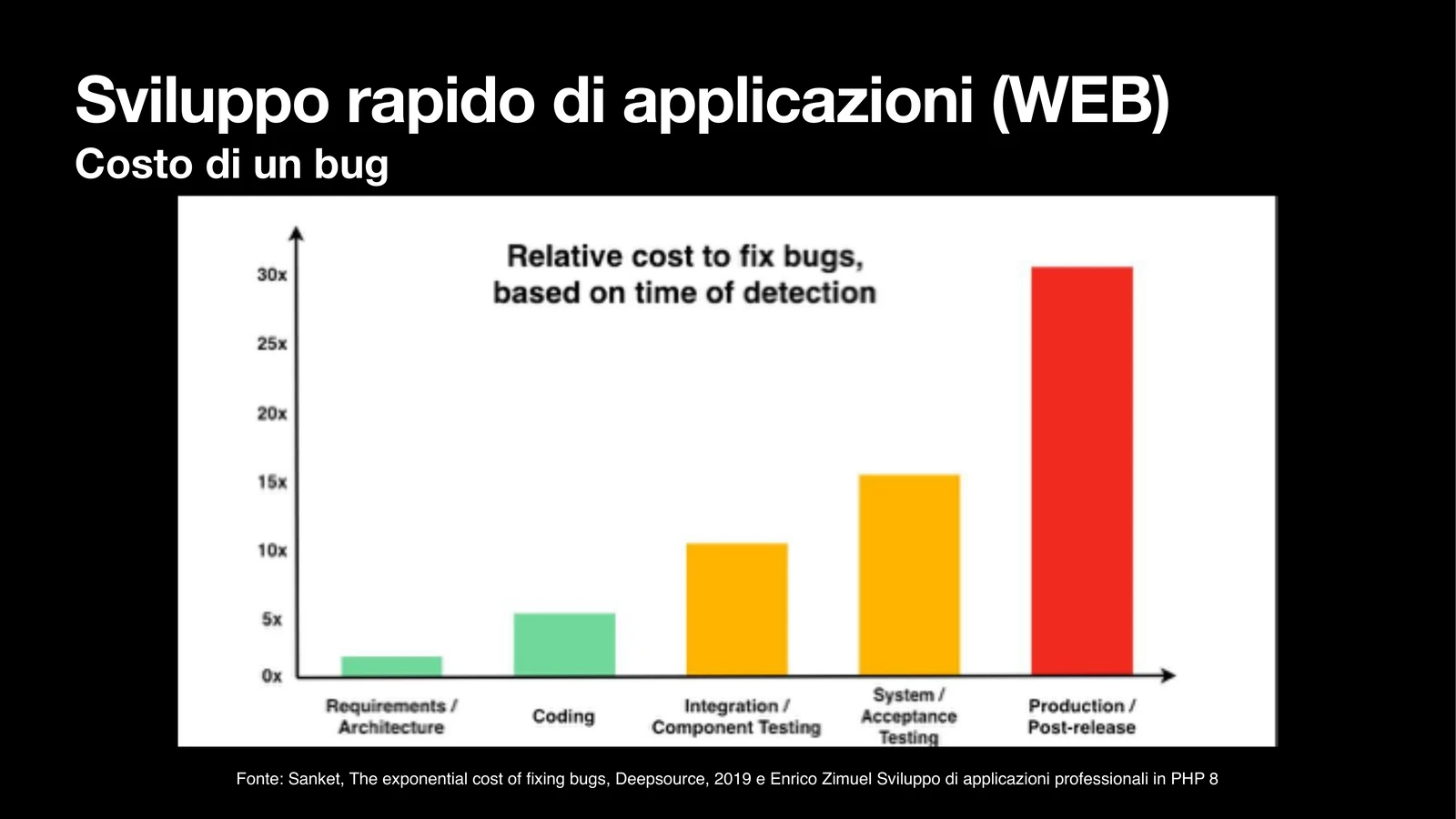
Slide dal mio talk al MOCA 2024: il costo di correggere un bug cresce in modo non lineare a seconda della fase in cui viene scoperto.
Trenta volte. E non sto parlando del bug in cui il pulsante è disallineato di due pixel. Sto parlando di bug funzionali veri: una transazione che si duplica, un permesso che si concede a chi non dovrebbe averlo, un calcolo che restituisce il risultato sbagliato in un caso limite. Quel tipo di bug, in produzione, non è mai solo un bug. È una serie di costi che si sommano: il fermo del servizio, il team che molla tutto per gestire l’urgenza, le comunicazioni ai clienti, i dati eventualmente da recuperare, la fiducia eventualmente persa, le implicazioni legali se di mezzo c’è una normativa.
I numeri esatti del grafico vanno presi per quello che sono, una stima media che varia molto da contesto a contesto. Ma il messaggio di fondo è solido e confermato da decenni di studi: più tardi scopri un problema, più ti costa risolverlo. Esponenzialmente, non linearmente.
E qui arriva la trappola del momento storico in cui siamo. Strumenti come l’AI ci permettono di scrivere codice molto più in fretta. Tutti, dal junior alla prima settimana al senior con vent’anni di esperienza, producono di più. Sembrerebbe un guadagno netto. Ma se la velocità di scrittura cresce e la cura nelle prime fasi cala, succede una cosa molto specifica: si sposta una quantità sempre maggiore di lavoro nelle fasi successive, dove ogni unità di lavoro costa molto, molto di più.
In altre parole: stiamo accelerando l’iniezione di problemi nelle prime fasi, dove correggerli costerebbe poco, per scoprirli nelle ultime, dove costano dieci, venti, trenta volte tanto.
“Ma tanto il TDD ormai è inutile, no?”
Questa frase, in varie salse, mi è stata detta più di una volta negli ultimi mesi. La logica dichiarata è sempre la stessa: tanto il codice lo scrive l’AI, scrivere prima i test è uno spreco, basta chiederle di generarli alla fine, e via.
Per un periodo, lo ammetto, ci ho creduto un po’ anch’io. È una di quelle idee che, in superficie, suona logica. Poi mi sono fermato a ragionarci, e ho capito che la frase nasce da un’idea sbagliata di cosa sia il TDD.
Il Test Driven Development non è “scrivere i test prima del codice” come adempimento burocratico. È un modo per costringersi a pensare alle invarianti del sistema prima di scriverle. Ti obbliga, in fase di analisi, a domandarti cosa il tuo pezzo di codice deve garantire, in che condizioni, con quali input ammessi, con quali output attesi, e cosa deve succedere quando le cose vanno storte. Il test è un effetto collaterale di questo pensiero. Il valore vero è il pensiero.
Quando deleghi all’AI sia il codice che i test, generati dopo, ottieni una cosa molto subdola: un sistema dove il codice e i test sono coerenti tra loro, ma nessuno dei due è ancorato a un’analisi vera del problema. I test verificano che il codice faccia quello che il codice fa. Una tautologia ben scritta.
E qui voglio raccontare una cosa che mi è capitata davvero, qualche mese fa. Mi era stato passato in gestione un software prodotto da un’azienda seria, fatta di persone competenti. Una delle prime cose che notai, andando a leggere la pipeline di CI, fu una regola scolpita lì dentro come un dogma: senza 100% di test coverage, niente deploy. Niente. Se la copertura scendeva anche di un solo punto percentuale, il deploy si bloccava, la build diventava rossa, e qualcuno doveva sistemare. Cento per cento tondo, sempre. Ogni singola riga di codice eseguita da almeno un test. Mi sarei dovuto rilassare. Niente bug, no?
In poche settimane ho scovato e corretto decine di bug. Bug veri, di logica, di gestione di casi limite, di assunzioni che il codice faceva implicitamente e che la realtà non rispettava.
Come è possibile? Succede, e succede continuamente, perché il coverage non misura quello che le persone credono che misuri. Misura quante righe di codice vengono eseguite da almeno un test. Non misura se quei test verificano qualcosa di significativo. Si può raggiungere serenamente il 100% di coverage scrivendo test che attraversano tutto il codice senza fare quasi nessuna asserzione, oppure facendo asserzioni banali, del tipo “questo metodo non solleva eccezioni”, che non escludono nessun comportamento sbagliato. Si può raggiungere il 100% di coverage senza essersi mai chiesti, neanche per un istante, cosa questo sistema dovesse non fare. E senza aver mai pensato a un solo caso limite.
Il 100% di coverage è un numero rassicurante. Sta nel cruscotto, sta nei badge, sta nelle slide del management, ti fa dormire la notte. Ed è esattamente per questo che è pericoloso: dà l’illusione di una rete di sicurezza che in realtà ha le maglie larghe quanto basta per lasciar passare quasi tutto. Il numero è alto, quindi tutti smettono di guardare.
L’AI, oggi, è uno splendido generatore di test che fanno salire il coverage. Sono test plausibili, leggibili, ben strutturati. Quasi nessuno di quei test, generato in automatico, ti dirà però qualcosa che non sapessi già. Saliranno i numeri, scenderà la qualità reale del controllo. Ed è così che si producono sistemi con metriche perfette e comportamenti disastrosi.
Il TDD, oggi, non è inutile. È più utile di prima, perché è una delle poche pratiche che ti costringe a fermarti a pensare in un’epoca in cui tutto invita ad accelerare. E perché ti riporta dove conta: non quante righe sono coperte, ma quali invarianti hai deciso, scrivendole, di proteggere.
L’ingegneria del software non sta scomparendo
Una delle narrazioni più diffuse del momento è che il software engineer tradizionale sia sulla via dell’estinzione. La verità, dal punto in cui sto io, è esattamente l’opposto. L’ingegneria del software non sta scomparendo. Si sta spostando.
Si sposta dalle dita verso la testa. Si sposta dal “saper scrivere il for loop più elegante” al “saper decidere se quel for loop ha senso esistere lì”. Si sposta dal produrre codice al curare la struttura, al disegnare le invarianti, al definire i confini del sistema, al mantenere coerente il modello del dominio. Si sposta verso quello che, in un altro articolo qualche mese fa, ho chiamato il famoso 30% del lavoro: l’architettura, la sicurezza, gli edge case, il pensiero critico.
L’AI è bravissima a produrre il 70%. Quel 70% però, da solo, è una commodity. Vale poco. Vale anzi pericolosamente poco, perché induce le persone a pensare che basti. Il valore è nel 30% restante, che è quello che l’AI non sa fare, perché richiede una visione d’insieme, una memoria di cosa è già successo nel sistema, una comprensione del contesto di business, e quel pizzico di paranoia salutare che si sviluppa solo dopo aver visto cose esplodere in produzione.
Quando io oggi uso l’AI, e la uso ogni giorno, intensamente, non lo faccio per scrivere meno codice. Lo faccio per concentrare le mie ore sulle decisioni che contano. Le decisioni di architettura, di modello dati, di confini di responsabilità tra moduli, di strategia di test, di gestione dei fallimenti. Su quelle non delego niente. Lì sto sveglio, lì applico esattamente le stesse pratiche di ingegneria del software che ho imparato in vent’anni.
E la stessa cosa vale per il framework giusto, per le librerie consolidate, per le convenzioni mature. Strumenti come Laravel non sono “scorciatoie”: sono accumulatori di decine di migliaia di ore di lavoro di ingegneri che hanno già pensato ai problemi che oggi tu stai cercando di risolvere. Affidarsi a un framework solido non è pigrizia. È riconoscere che esiste una cosa chiamata stato dell’arte, che vale la pena conoscerlo, e che il tuo valore aggiunto è da un’altra parte.
Tutti possono scrivere software. Quasi nessuno sa mantenerlo.
Questa è la frase che mi gira in testa da settimane. Tutti possono scrivere software. È vero, finalmente è vero, ed è un’ottima notizia. Il bambino che oggi vuole costruire la sua piccola utility ha strumenti che io a quell’età potevo solo sognare. La barriera di ingresso è crollata. Va bene così.
Ma scrivere un software piccolo, con tre funzionalità, un utente, e zero responsabilità, è un esercizio molto diverso dal tenere in vita un sistema con centinaia di funzionalità, migliaia di utenti, integrazioni con il mondo esterno, e dati di cui qualcuno è responsabile. La distanza tra le due cose è enorme. È la stessa distanza che c’è tra costruire una capanna nel giardino e progettare un grattacielo. La capanna sta in piedi anche se la fai male. Il grattacielo no.
Mi è successa una cosa, qualche settimana fa, che mi ha lasciato sconcertato. Un amico mi chiede di dare un’occhiata a un software che ha sviluppato, e che ha già messo in produzione, con tanto di annuncio entusiasta su X. Vado a guardare. La prima sorpresa, fino a un certo punto digeribile, è scoprire che il software è stato vibe-codato per intero da persone che non sono informatici. Lo capisco, oggi è possibile, è anche una conquista. Quello che non mi aspettavo è quello che trovo nei primi cinque minuti di analisi.
Le API key dei servizi esterni, in chiaro nel codice client. Le tabelle del database, ospitate su Supabase, completamente esposte al client perché nessuno aveva attivato le policy di Row Level Security: chiunque, dal browser, con la chiave pubblica del progetto, poteva leggere e scrivere qualunque tabella. Lo storage S3 a cui chiunque, con la stessa chiave, poteva caricare file arbitrari. Mi sono fermato lì. Non sono andato oltre, non ne avevo bisogno, e francamente non ne avevo voglia.
Quel software era online. Aveva utenti veri, dati veri, fiducia vera di persone che non avevano alcun modo di sapere che le loro informazioni stavano dietro una porta lasciata aperta. Nessuno di chi l’aveva costruito, ne sono certo, voleva fare male a quegli utenti. Ma il punto è proprio questo: la buona fede non basta, e non è mai bastata.
E noi, in quanto industria, stiamo per produrre una quantità enorme di codice scritto come si costruirebbe una capanna, ma destinato a reggere come un grattacielo. Quel codice arriverà in produzione. Servirà persone vere. Gestirà soldi veri, dati veri, vite vere. E quando l’entropia farà il suo lavoro, e lo farà, perché è il suo lavoro, qualcuno dovrà pulire.
Quel qualcuno, oggi, è ancora un essere umano. Un ingegnere del software con la pazienza di leggere il disastro, la lucidità di capire dove si è incrinato, e l’onestà di dire: questo va rifatto.
Torno al monitor
Torno alla scrivania con l’infuso fumante. Riapro Neovim, riapro il terminale. Guardo lo schermo per qualche minuto in silenzio.
Potrei dire al collega che sì, ci sono delle cose da sistemare, ma con due settimane di interventi spot lo si rende presentabile. Sarebbe la risposta facile. Sarebbe anche, quasi sicuramente, una risposta disonesta, perché conosco bene la storia che mi aspetta dopo. Toppe sopra toppe. Bug che spuntano in produzione in punti del codice che, in apparenza, non c’entrano nulla con la modifica appena fatta. Ogni nuova feature che richiede tre giorni solo per capire come incastrarla in quella struttura. Una squadra che, invece di costruire valore, passa il tempo a fare manutenzione difensiva, a scrivere note di rilascio piene di fix temporaneo per evitare regressione su X. E ogni fix temporaneo, lo sappiamo tutti, ha un nome diverso da quello che dichiara: si chiama debito tecnico, e matura interessi.
Ed è qui che torno al punto da cui sono partito. L’entropia, in quella codebase, ha già preso troppa velocità. Ogni intervento spot non la frena: la accelera. Il costo del mantenimento, che in qualunque software è già la voce di spesa più alta del ciclo di vita, in un sistema così cresce in modo non lineare. Più vai avanti a tappare, più diventa caro andare avanti.
Ricomincio da capo. Apro un repository nuovo, vuoto. Ma non scrivo codice. Comincio a pensare. Apro il taccuino e disegno il modello del dominio prima ancora di toccare la tastiera. Decido i confini dei moduli, le responsabilità di ognuno, i contratti tra le parti, le invarianti che voglio proteggere. Decido cosa il sistema deve fare e, soprattutto, cosa non deve fare. È in questa fase che si gioca quasi tutto. Ed è la fase in cui l’AI, da sola, non sa muoversi: non ha la mia memoria del dominio, non sa cosa è già esploso in passato, non conosce i vincoli non scritti del business.
Sì, la uso. La uso eccome, e in tutto questo articolo non ho mai detto il contrario. La uso intensamente, ogni giorno, in modo strutturale al mio lavoro. Non sono qui a fare il vecchio nostalgico che difende la tastiera meccanica. Sono qui a dire che fa una differenza enorme come la usi.
Quando il modello mentale comincia a essere chiaro, apro Claude Code e lo uso come compagno di esplorazione, non come stenografo. Lavoro per spike. Lo spike, nel mondo dello sviluppo software, è un’idea di Kent Beck, uno dei padri dell’Extreme Programming. È un piccolo esperimento di codice, scritto in fretta e con l’esplicita intenzione di buttarlo via, che serve a rispondere a una domanda tecnica precisa. Questa libreria gestisce davvero il caso Y come penso? Questo modello dati regge se lo carico con un milione di record? Questa scelta architetturale ha il profilo di latenza che mi serve? Lo spike non è il prodotto. È una sonda nel terreno. Si scrive, si fa rispondere alla domanda, e si butta. Quello che resta è l’informazione, non il codice.
Con un agent come Claude Code, gli spike sono diventati molto più veloci. Posso esplorare in mezz’ora ipotesi di architettura che prima mi avrebbero richiesto una giornata. Posso confrontare due approcci nello stesso tempo che prima me ne richiedeva uno. Ma sono io a decidere quali spike fare, io a leggere i risultati con occhio critico, io a stabilire quale ipotesi promuovere e quale scartare. L’AI non porta le domande giuste: le porto io, l’AI mi aiuta a rispondere in fretta.
Solo dopo, quando l’architettura ha retto la prova degli spike, scrivo i primi test veri, quelli che cristallizzano le invarianti del sistema (anzi, sono io a dire a Claude Code quali test scrivere e come scriverli, caso per caso, asserzione per asserzione). Non perché un consulente del 2010 me lo direbbe, ma perché ho bisogno di obbligarmi a fissare per iscritto cosa questo sistema deve garantire, prima di sbattermi a farlo girare. È solo a quel punto che chiedo a Claude Code di aiutarmi a scrivere il codice di produzione, sotto la guida di una struttura che ho già deciso io, controllando ogni pezzo che produce e respingendo quello che non rispetta le regole che ho fissato.
Il pensiero resta mio. La struttura resta mia. La responsabilità resta mia. L’AI è un acceleratore potentissimo, ma la direzione la metto io. È in questa direzione, non nelle dita sulla tastiera, che vive l’ingegneria del software che ho imparato in vent’anni. E nessun agent, oggi, può prendersela addosso al posto mio.
È una perdita di tempo? Forse. Forse una volta ci si pensa prima.
L’entropia, però, non si delega.
Non si è mai potuta delegare. Non con le piattaforme low-code di vent’anni fa, non con i framework full-stack di dieci anni fa, non con l’AI di oggi. Cambiano gli strumenti, cambia la velocità, cambia chi può iniziare. Quello che non cambia è chi, alla fine, deve mettere ordine. E questo, ancora per un bel pezzo, sarà un lavoro umano.
Anzi, sarà sempre più un lavoro umano. Perché più velocemente produciamo disordine, più qualcuno dovrà avere le competenze, la pazienza, e la testa, per riportare ordine.
E a quel qualcuno, qualunque sia la sua età e qualunque sia il suo titolo di studio, io continuerò a chiamarlo ingegnere del software.